

/* Redis */
Remote Dictionary Server
- "원격(Remote)" → 네트워크를 통해 접근할 수 있음.
- "딕셔너리(Dictionary)" → Key-Value 저장 방식 사용.
- "서버(Server)" → 클라이언트 요청을 받아 데이터를 저장/제공하는 서버 역할.
/* 특징 */
- In-Memory: 모든 데이터를 RAM에 저장 (백업 / 스냅샷 제외)
- Single Threaded: 단일 Thread에서 모든 task 처리
- Cluster Mode: 다중 노드에 데이터를 분산 저장하여 안정성 & 고가용성 제공
- 클러스터 모드에서 데이터는 샤딩을 통해 특정 노드에 저장되고, 그 노드의 위치는 해싱(Hashing)을 통해 결정
조회할 때도 해싱을 통해 해당 데이터가 저장된 노드를 찾아서 요청을 보낸 후 값을 조회
- 클러스터 모드에서 데이터는 샤딩을 통해 특정 노드에 저장되고, 그 노드의 위치는 해싱(Hashing)을 통해 결정
- Persistence: RDB(Redis Database) + AOF(Append only file) 을 통해 영속성 옵션 제공
- Pub/Sub: 발행(Publisher)과 구독(Subscriber)을 기반으로 하는 비동기 메시징 시스템
/* 장점 */
- 높은 성능: 모든 데이터를 메모리에 저장하기 때문에 빠른 읽기/쓰기 속도 보장
- 다양한 Data Type 지원
- 다양한 클라이언트 라이브러리 지원
/* 사용사례 */
- Caching
- Rate Limiter
- Message Broker
- 실시간/ 분석 계산: 순위표, 반경 탐색, 방문자 수 계산
- 실시간 채팅
/* Persistence */
Redis는 주로 캐시로 사용되지만, 데이터 영속성을 위한 옵션도 제공한다.
SSD와 같은 영구적인 저장 장치(디스크)에 데이터 저장
- RDB
- Redis의 전체 데이터를 일정 주기마다 스냅샷(Snapshot) 형태로 저장하는 방식.
- .rdb 파일이 생성되며, Redis가 다시 시작될 때 이 파일을 로드하여 복구
- redis.conf 에서 save 명령어를 사용하여 주기적으로 저장 가능
✔ 디스크 I/O가 적어 성능이 우수함 (백그라운드에서 실행됨)
✔ 빠른 복구 가능 (파일 하나만 있으면 전체 데이터 복구 가능)
✔ 파일 크기가 작음 (스냅샷 방식이므로 압축됨)
❌ 최신 데이터 유실 가능 (마지막 스냅샷 이후 변경된 데이터는 저장되지 않음)
❌ 스냅샷 저장 시 순간적으로 CPU/메모리 사용 증가 가능
save 900 1 # 900초(15분) 동안 1개 이상의 키가 변경되면 저장
save 300 10 # 300초(5분) 동안 10개 이상의 키가 변경되면 저장
save 60 10000 # 60초 동안 10,000개 이상의 키가 변경되면 저장
- AOF
- 모든 쓰기 연산 (SET 등)을 로그 파일에 기록
- .aof 파일에 연산을 순차적으로 기록하며, Redis가 재시작될 때 해당 연산들을 다시 실행하여 데이터 복구.
appendonly yes # AOF 활성화
appendfsync always # 모든 연산을 즉시 디스크에 기록 (안전하지만 느림)
appendfsync everysec # 1초마다 기록 (일반적으로 사용)
appendfsync no # OS가 자동으로 기록할 때까지 대기 (성능은 좋지만 안정성 낮음)
✔ 데이터 유실 가능성이 낮음 (모든 변경 사항을 기록)
✔ 명령어 로그 기반 복구 가능 (전체 덤프 대신 개별 연산을 기록)
✔ 실시간 백업 가능 (파일에 지속적으로 기록되므로 실시간 동기화 가능)
❌ 파일 크기가 커질 수 있음 (모든 연산이 기록됨)
❌ 쓰기 성능이 낮을 수 있음 (appendfsync 설정에 따라 다름)
❌ 복구 시간이 길 수 있음 (많은 명령을 다시 실행해야 함)
Redis에서는 RDB와 AOF를 함께 사용할 수도 있음.
이 경우 Redis는 AOF 파일을 우선적으로 사용하여 복구.
/* Cache-Aside Pattern */
애플리케이션이 먼저 캐시에서 데이터를 조회(Cache Hit)하고, 없으면(Cache Miss) 데이터베이스에서 가져온 후 캐시에 저장하는 방식
❌ Cache Miss 발생 시 응답 속도가 느릴 수 있음 (DB 조회 필요)
❌ 데이터 변경 시 캐시를 직접 무효화해야 함
/* String */
문자열, 숫자, JSON 등을 저장한다.
$ SET lecture inflearn-redis
$ MSET price 100 language ko
$ MGET lecture price language
$ INCR price
$ INCRBY price 10
$ SET lecture '{"lecture": "inflearn-redis", "language": "en"}'
$ SET inflearn-redis:ko:price 200
/* List*/
String을 Linked List로 저장 -> push / pop에 최적화 O(1)
Queue / Stack 구현에 사용된다.
$ LPUSH queue job1 job2 job3
$ RPOP queue
$ LPUSH stack job1 job2 job3
$ LPOP stack
$ LPUSH queue job1 job2 job3
$ LRANGE queue -2 -1 # 뒤에서 두 번째(-2)부터 마지막(-1)까지의 요소를 조회.
$ LTRIM queue 0 0 # 0번 인덱스(첫 번째 요소)만 남기고 나머지 요소 삭제.
/* Set*/
Set Operation을 사용할 수 있다. (intersection, union, difference)
$ SADD user:1:fruits apple banana orange orange
$ SMEMBERS user:1:fruits # 1) "apple" 2) "banana" 3) "orange"
$ SCARD user:1:fruits # (integer) 3 요소 개수
$ SISMEMBER user:1:fruits banana # (integer) 1
$ SADD user:2:fruits apple lemon
$ SINTER user:1:fruits user:2:fruits # apple
$ SDIFF user:1:fruits user:2:fruits # banana orange
$ SUNION user:1:fruits user:2:fruits # 1) "apple" 2) "banana" 3) "orange" 4) "lemon"
/* Hash*/
field-value 구조를 갖는 데이터 타입.
HSET lecture lecture "inflearn-redis"
HSET lecture language "en"
HGET lecture lecture # inflearn-redis
HGET lecture language # en
$ HSET lecture name inflearn-redis price 100 language ko
$ HGET lecture name # inflearn-redis
$ HMGET lecture price language invalid
$ HINCRBY lecture price 10 # 110
/* Sorted Sets*/
Unique String이 Key, Score 점수가 Value 이다.
내부적으로 Skip List + Hash Table로 이루어져 있다. Score 값에 따라 정렬 유지.
값이 동일하면 사전 순으로 정렬
zadd scores 30 TeamB
zadd scores 10 TeamA
zadd scores 50 TeamC
zrange scores 0 -1 # TeamA TeamB TeamC
zrange scores 0 2 rev withscores # TeamC 50 TeamB 30
zrank scores TeamA # 0
/* Streams */
append-only log에 consumer groups과 같은 기능을 더한 자료 구조
unique id를 통해 하나의 entry를 읽을 때 O(1)
Consumer Group을 통해 분산 시스템에서 다수의 consumer가 event 처리
XADD news_stream * message "hello" 스트림에 메시지 추가
XGROUP CREATE news_stream news_group $ news_group 컨슈머 그룹 생성
XREADGROUP GROUP news_group consumer1 COUNT 2 STREAMS news_stream > Consumer1이 새 메시지를 읽음
XPENDING news_stream news_group 컨슈머 그룹에서 미처리 메시지 확인
XACK news_stream news_group <ID> Consumer가 메시지 처리를 완료했음을 확인
XCLAIM news_stream news_group consumer2 60000 <ID> Consumer2가 처리되지 않은 메시지를 가져옴/* Geospatial*/
좌표를 저장하고, 검색하는 데이터 타입
거리 계산, 범위 탐색 등 지원
$ GEOADD seoul:station 126.923917 37.556944 hong-dae 127.027583 37.497928 gang-nam
$ GEODIST seoul:station hong-dae gang-nam KM/* Bitmaps */
String에 binary operation을 적용한 것
사용 사례: 날짜 별로 사용자가 로그인 했는지 여부, 로그인 한 사용자 개수
$ SETBIT user:log-in:23-01-01 123 1
$ SETBIT user:log-in:23-01-01 456 1
$ SETBIT user:log-in:23-01-02 123 1
$ BITCOUNT user:log-in:23-01-01 # 2
$ BITOP AND result user:log-in:23-01-01 user:log-in:23-01-02
$ BITCOUNT result # 1
$ GETBIT result 123 # 1
/* HyperLogLog */
매우 적은 메모리를 사용하여 대략적인 개수를 추정하는 데이터 구조
중복을 제거한 유니크한 개수(카디널리티, Cardinality)를 효율적으로 계산
사용 사례 : 방문자 수 추적, 광고 노출 수
$ PFADD fruits apple orange grape kiwi
$ PFCOUNT fruits
/* BloomFilter */
element가 집합 안에 포함되었는지 확인하는 확률형 자료 구조
false positive: element가 집합에 실제로 없는데 있다고 잘못 예측하는 경우를 인지하고 있어야 한다.
$ BF.MADD fruits apple orange
$ BF.EXISTS fruits apple
$ BF.EXISTS fruits grape
/* 데이터 만료 관련 명령 */
$ SET greeting hello
$ EXPIRE greeting 10
$ TTL greeting
# -1: TTL 설정이 안되어 있다. redis가 종료되지 않는 이상 계속 메모리에 저장
# 5: 5초 후에 만료
# -2: 이미 만료가 되어 삭제됨
$ GET greeting
/* NX / XX */
- NX: 해당 Key가 존재하지 않는 경우에만 SET
- XX: 해당 Key가 이미 존재하는 경우에만 SET
- SET이 동작하지 않은 경우 (nil) 응답
$ SET greeting hello NX # OK
$ GET greeting # hello
$ SET greeting hi XX # OK
$ GET greeting # hi
$ SET invalid abcd XX # (nil)
$ SET greeting hello NX # (nil)/* Pub Sub */
Publisher와 Subscriber가 서로 알지 못해도 통신이 가능하도록 decoupling된 패턴.
Publisher는 Subscriber에게 직접 메시지를 보내지 않고, Channel에 Publish
Subscriber는 관심이 있는 Channel을 필요에 따라 Subscribe하며 메시지 수신
$ SUBSCRIBE ch:order ch:payment
$ PUBLISH ch:order new-order
$ PUBLISH ch:payment new-payment/* Pipleline */
다수의 commands 를 한 번에 요청하여 네트워크 성능을 향상 시키는 기술. Round-Trip Times 최소화,
/* 트랜잭션 */
다수의 명령을 하나의 트랜잭션으로 처리. 원자성 보장
중간에 에러가 발생하면 모든 작업 RollBack
하나의 트랜잭션이 처리되는 동안 다른 클라이언트의 요청이 중간에 끼어들 수 없음
$ MULTI
$ INCR foo
$ DISCARD # queue에 있는 작업 다 안함
$ EXEC # queue에 있는 작업 다 실행
/* 활용1 - One Time Password */
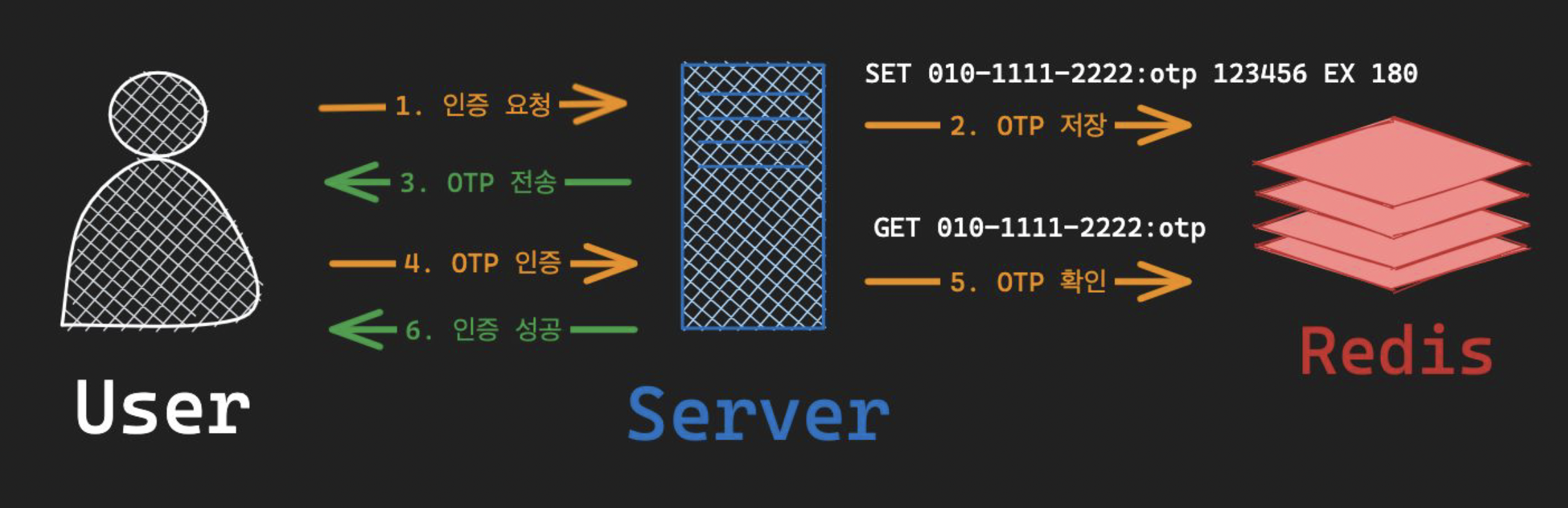
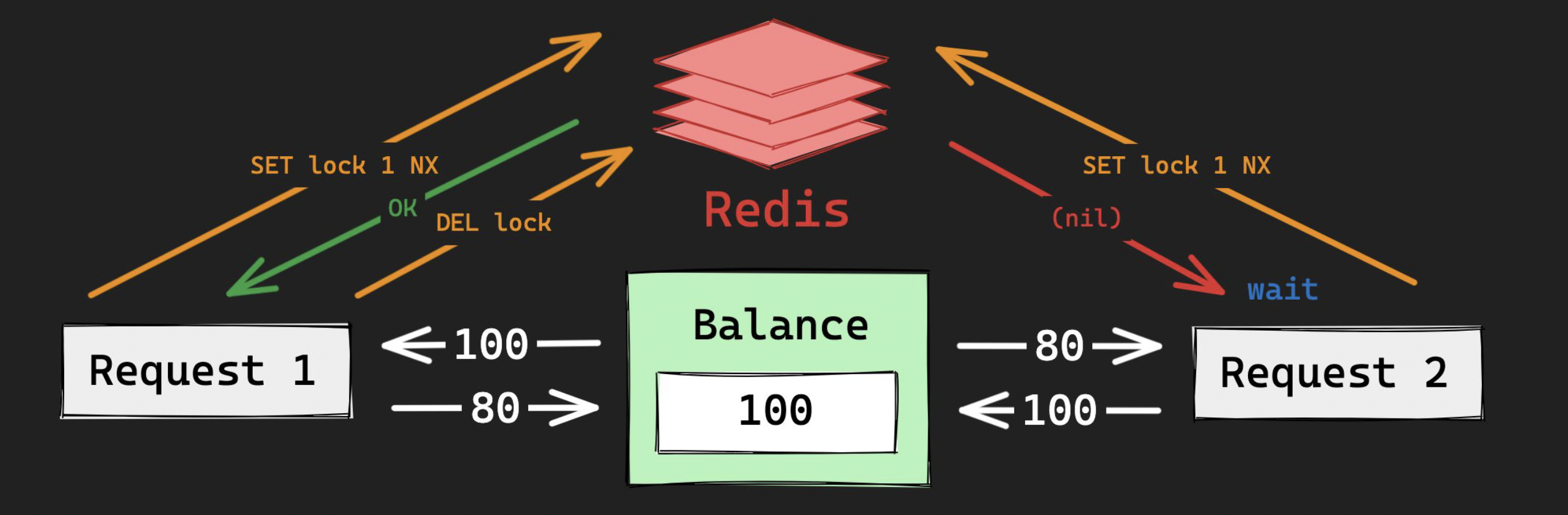
/* 활용2 - 분산 락 */
/* 활용3 - Rate Limiter */
시스템 안정성/보안을 위해 요청 수 제한
Fixed-window Rate Limiting. (고정 윈도우)

/* 활용4 - SNS Activity Feed (List) */
사용자 또는 시스템과 관련된 활동이나 업데이트를 시간순으로 정렬하여 보여줌

/* 활용5 - 장바구니 (Set) */
장바구니는 임시의 가상 공간

/* 활용6 - 로그인 세션 (Hash) */
로그인 세션: 사용자의 로그인 상태를 유지하기 위한 기술
사용 사례: 동시 로그인 제한, 로그인 시 세션의 개수를 제한하여, 동시에 로그인 가능한 디바이스 개수를 제한

/* 활용7 - Rate Limiter 슬라이딩 윈도우 (Sorted Set) */
$ ZADD user:123:rate_limit <timestamp> request
$ ZREMRANGEBYSCORE user:123:rate_limit 0 <current_timestamp - 60>
$ ZCOUNT user:123:rate_limit <current_timestamp - 60> <current_timestamp>
/* 활용8 - 반경 탐색 (Geospatial) */
위치를 활용하여 지도 상의 가상의 경계 정의
$ GEOADD gang-nam:burgers
127.025705 37.501272 five-guys
127.025699 37.502775 shake-shack
127.028747 37.498668 mc-donalds
127.027531 37.498847 burger-king
$ GEORADIUS gang-nam:burgers
127.027583 37.497928 0.5 km # burger-king, mc-donalds, five-guys/* 활용9 - 온/오프라인 상태 확인 (Bitmap) */

SETBIT user:status 123 1 # 유저 123이 온라인
EXPIRE user:status 300 # 300초(5분) 동안 업데이트 없으면 자동 삭제/* 활용10 - 방문자 수 계산 (HyperLogLog) */

/* 활용11 - 중복 이벤트 제거 (BloomFilter) */

/* O(N) 명령어 */
대부분의 연산은 O(1)이지만 일부 명령은 O(N)이다.
- Keys -> SCAN 명령어로 대체
SCAN <cursor> [MATCH <pattern>] [COUNT <count>]
SCAN 0 MATCH session:* COUNT 50- SMEMBERS: Set의 모든 member 반환
- HGETALL: Hash의 모든 field 반환
- SORT: List, Set, ZSet의 item 정렬하여 반환
'데이터베이스' 카테고리의 다른 글
| [DB] 트랜잭션 격리수준 Isolation Level (2) | 2024.10.14 |
|---|---|
| [MySQL] 인덱스 (0) | 2024.06.03 |
| SQL 문법 정리 #1 (1) | 2023.11.13 |
| MySQL 리눅스와 터미널연결 및 MySQL 설치 (0) | 2023.10.27 |
| DB (MySQL) 공부시작 (1) | 2023.10.26 |



